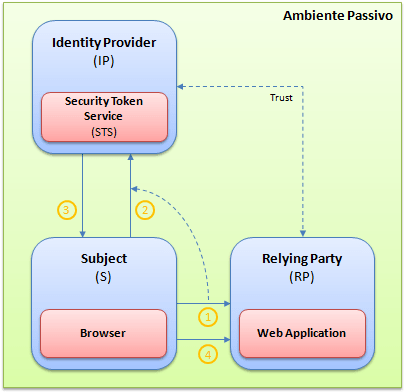
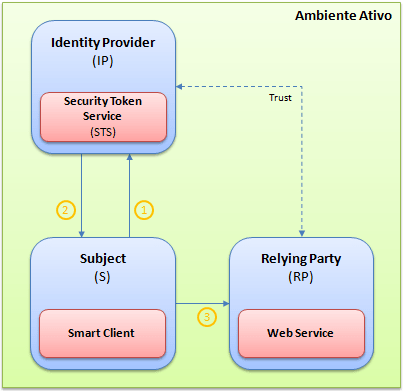
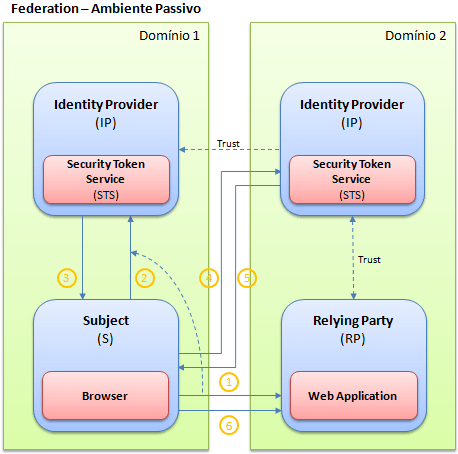
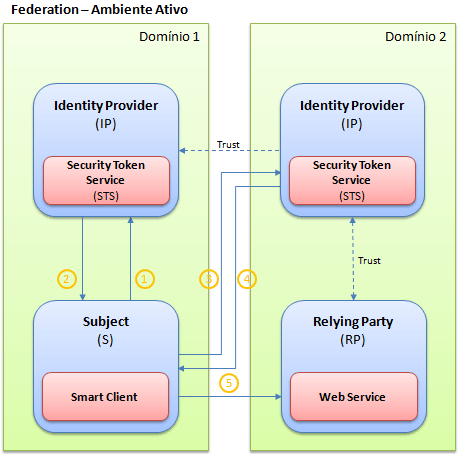
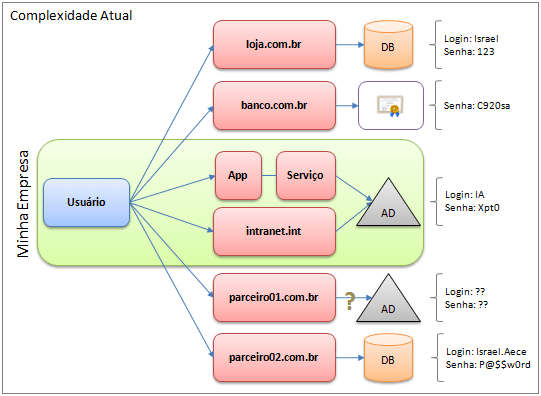
O novo modelo de autenticação e autorização possui três elementos, conhecidos como: Identity Providers, Relying Parties e Subjects. Já falamos sobre o papel que cada um deles exerce dentro deste novo sistema em um artigo anterior. Mas como utilizar estes elementos dentro das nossas aplicações, ou melhor, como fazer com que uma aplicação seja candidata à receber claims emitidas por algum identity provider?
É justamente neste momento que entra em cena um dos grandes pilares que compõem o novo modelo de autenticação e autorização, que é o Windows Identity Foundation (WIF). Através deste novo framework, a Microsoft disponibiliza uma série de tipos que podem ser utilizados não somente para construir aplicações que receberão as claims (relying parties), mas também para estender alguns recursos existentes, como por exemplo, tipos para a criação de um STS (Security Token Service) customizado, criar extensões para o ADFS 2.0, entre outras coisas.
O WIF expõe uma série de tipos para a criação das relying parties, e o uso de cada um destes tipos está condicionado ao tipo de ambiente que está sendo aplicado, que pode ser passivo ou ativo. A finalidade deste artigo é abordar os tipos comuns, e que são úteis para qualquer um destes ambientes. Tipos específicos, utilizados pelos ambientes passivos/ativos e também para estensibilidade, serão abordados em futuros artigos.
Antes de falar diretamente das classes do WIF, é importante dizer que desde a primeira versão do WCF, já havia um assembly chamado System.IdentityModel.dll, que fornece classes para construir serviços que suportem claims. O problema é que muitas outras classes que também são necessárias para executar algumas outras tarefas não eram públicas, tornando um desafio para aqueles que estão precisavam disso. E para complicar ainda mais, não havia um modelo de programação uniforme, que poderíamos facilmente acoplar à execução das aplicações, pois não mantém compatibilidade com o formato tradicional de segurança imposto pelo .NET Framework. O papel do WIF é unificar esse modelo de autenticação e autorização, tornando algo comum para qualquer tipo de aplicação que você desenvolva.
Desde as primeiras versões do .NET Framework, há duas interfaces que controlam a autenticação e autorização dos usuários: IIdentity e IPrincipal. A primeira é reponsável por representar o usuário que está autenticado, fornecendo entre outras informações, o seu nome. Já a interface IPrincipal, representa o contexto de segurança daquele usuário, e fornece uma propriedade chamada Identity do tipo IIdentity e um método chamado IsInRole, que dado uma string representando um papel, retorna um valor boleano indicando se o usuário está ou não contido nele.
E onde elas estão dentro da aplicação? Dentro do namespace System.Threading existe uma classe chamada Thread. Essa classe determina como controlar uma thread dentro da aplicação, e que entre vários membros, possui uma propriedade chamada CurrentPrincipal que recebe a instância de um objeto que implementa a interface IPrincipal. É através desta propriedade que devemos definir qual será a identity e a principal que irá representar o contexto de segurança para a thread atual. Para maiores detalhes, consulte o capítulo 9 deste livro.
Depois de uma pequena recapitulação, vamos começar a abordar o que temos à disposição dentro do WIF. As classes que veremos a seguir, estão dentro do assembly Microsoft.IdentityModel.dll e debaixo do namespace Microsoft.IdentityModel.Claims. Como uma das preocupações da Microsoft foi manter compatibilidade com o modelo de segurança do .NET Framework, ela criou versões específicas das interfaces IIdentity e IPrincipal, que são chamadas de IClaimsIdentity e IClaimsPrincipal. Abaixo temos a imagem do diagrama que representa a hierarquia entre as interfaces de identity:

A primeira propriedade que ela fornece, chamada de Actor, é do tipo IClaimsIdentity, que é útil em cenários de delegação, e em conjunto com ela, temos a propriedade BootstrapToken, mas veremos mais detalhes sobre elas em um artigo futuro, que abordará exatamente este cenário. A terceira propriedade, chamada Claims, é uma das mais importantes para este modelo de autenticação/autorização. Esta propriedade expõe uma coleção do tipo ClaimCollection, onde cada elemento é representado por uma instância da classe Claim, que detalheremos mais adiante. Label é uma propriedade de tipo string, que recebe uma informação qualquer, que personaliza aquela identidade.
Como sabemos, a propriedade Name exposta pela interface IIdentity, retorna o nome do usuário atual, enquanto o método IsInRole, faz verificações baseando-se nos papéis daquele mesmo usuário. Como esses membros são popularmente utilizados, como iremos preencher essas informações? É justamente aqui que as propriedades NameClaimType e RoleClaimType são úteis. Como todas as informações emitidas por um identity provider chegam para uma relying party através de claims, é necessário saber qual claim representa o nome do usuário (IIdentity.Name) e o papel (IPrincipal.IsInRole). Geralmente, cada claim nada mais é que uma string, representado por uma URI, mas não que isso seja obrigatório. Abordaremos mais detalhes sobre a sua representação quando falarmos à respeito da classe Claim, ainda neste artigo.
Observação: Como disse anteriormente, claims podem ser muito mais expressivas do que simplesmente ter o nome do usuário e seus papéis. A necessidade de termos as propriedades NameClaimType e RoleClaimType, é justamente para manter compatibilidade com todo o legado de segurança que já conhecemos e/ou temos em aplicações que fazem uso do .NET Framework.
Da mesma forma que vimos acima, a interface IClaimsPrincipal também herda diretamente da interface IPrincipal, incluindo apenas uma única propriedade, chamada de Identities, que é do tipo ClaimsIdentityCollection, ou seja, uma coleção onde cada elemento dentro dela é do tipo IClaimsIdentity. Na maioria das vezes, essa propriedade somente terá um único elemento, representando o usuário atual, entretanto, em cenários mais avançados, pode haver várias identidades de um mesmo usuário, emitidos por orgãos diferentes. A imagem abaixo ilustra a herança entre essas duas interfaces:

Como vimos acima, a interface IClaimsIdentity, expõe uma coleção de claims. Cada elemento é representado por uma instância da classe Claim, e como o próprio nome diz, representa uma claim entre as várias que um identity provider pode emitir para um determinado subject. Como já comentado em artigos anteriores, cada claim é uma espécie de afirmação que um identity provider emite para algum subject, e entre elas, podemos ter o nome do usuário e os papéis em que ele se encontra.

Como podemos notar na imagem acima, a classe Claim fornece várias propriedades que descreve cada uma delas. A propriedade ClaimType, retorna uma string, que na maioria das vezes é uma URI, representando o que aquela claim significa (se é o nome, e-mail, data de nascimento, etc.). A propriedade Issuer também retorna uma string com o nome daquele que emitiu a claim. OriginalIssuer tem sentindo quando trabalhamos em ambientes federados, onde pode haver mais do que um emissor. Properties é uma propriedade que expõe um dicionário de strings, que permite adicionarmos informações extras sobre uma determinada claim. A propriedade Subject é clara, retorna uma instância do tipo IClaimsIdentity que representa o subject ao qual aquela claim pertence. A propriedade Value retorna o valor daquela claim (“Israel Aece”, “ia@israelaece.com”, 05/09/1981, etc.). E, finalmente, temos a propriedade ClaimValue, que ajuda a definir o tipo daquela claim. Essa propriedade é útil durante o processo de deserialização do token, fornecendo informações a respeito do tipo que aquela claim é. Há uma classe estática chamada ClaimValueTypes, que possui várias constantes públicas que já são conhecidas, tais como: Integer, DateTime, Double, etc.
As interfaces não são “instanciáveis”, e justamente por isso, precisamos de classes que implementem esses recursos expostos pelas interfaces apresentadas acima. E para isso, a Microsoft disponibilizou também as classes ClaimsIdentity e ClaimsPrincipal, que implementam as interfaces IClaimsIdentity e IClaimsPrincipal, respectivamente. Além dos membros que elas são obrigadas a implementarem, ainda há na classe ClaimsPrincipal, métodos estáticos, que auxiliam na criação de uma principal deste tipo, extraindo as informações de objetos que já são conhecidos, como HttpContext ou IIdentity. A imagem abaixo ilustra a estrutura destas duas classes:

Essas classes são, na maioria das vezes, instanciadas pelo próprio runtime do WIF, que as cria de acordo com o token que é recebido do identity provider. Depois de criadas, o próprio WIF armazena a instância da classe ClaimsPrincipal dentro da propriedade ThreadPrincipal, exposta pela classe Thread, ou se estivermos falando de uma aplicação ASP.NET, ela – também – estará acessível através da propriedade estática User da classe HttpContext.
Em ambos os casos, essas propriedades recebem e retornam classes que implementam a interface IPrincipal, e graças ao polimorfismo, podemos definir classes que implementam a interface IClaimsPrincipal nestas mesmas propriedades. O único detalhe importante, é que para extrair e ter acesso à todas as propriedades expostas pela interface IClaimsPrincipal, será necessário efetuar a conversão, assim como é mostrado no trecho de código abaixo:
IClaimsPrincipal principal = Thread.CurrentPrincipal as IClaimsPrincipal;
if (principal != null)
{
IClaimsIdentity identity = (IClaimsIdentity)principal.Identity;
Console.WriteLine(“Nome: {0}”, identity.Name);
Console.WriteLine(“Label: {0}”, identity.Label);
foreach (Claim c in principal.Claims)
Console.WriteLine(“{0}: {1}”, c.ClaimType, c.Value);
}
Obviamente que essas classes por si só não funcionam. Quem faz grande parte do trabalho para a criação de cada uma delas é o runtime do WIF, e a sua configuração depende diretamente de qual tipo de aplicação estaremos utilizando (web ou serviços). O que vimos no decorrer deste artigo, são as classes que representam um subject para uma relying party, e isso não importa o tipo de aplicação que estamos utilizando. Em futuros artigos, analisaremos como configurar cada uma delas, e vamos notar que essas propriedades já estarão devidamente preenchidas.
Conclusão: Este artigo apresentou os novos tipos que temos a nossa disposição para a criação de aplicações (relying parties), que consomem claims geradas por algum identity provider. Reparamos também que o modelo de programação segue a mesma estrutura imposta pelo .NET Framework, e que por isso, podemos reaproveitar o conhecimento adquirido anteriormente, para ter um impacto bem menor quando migramos para este novo modelo.