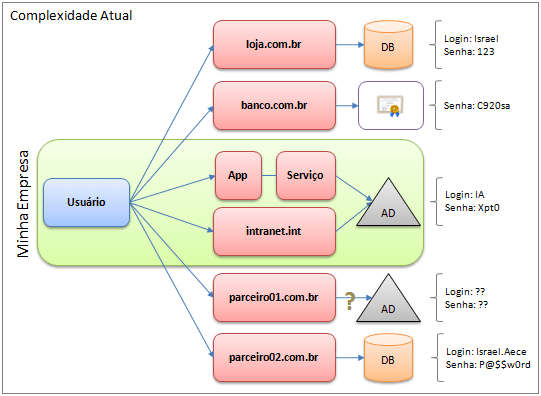
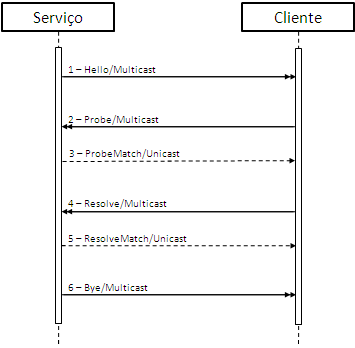
No artigo anterior, falamos um pouco sobre os problemas conhecidos quando lidamos com a autenticação e autorização em uma aplicação, e no final dele, falei superficialmente sobre os produtos que a Microsoft tem desenvolvido para tornar a utilização do modelo baseado em claims mais simples. A partir de agora, vamos analisar os elementos que compõem o sistema de identidade, analisando o fluxo e alguns conceitos que circundam este modelo, e que é independente de tecnologia.
Tudo o que veremos a seguir é conhecido como Identity MetaSystem, que consiste em uma infraestrutura que abstrai todas as operações necessárias para promover tudo o que é preciso para suportar identidades em cima da internet, fornecendo uma arquitetura interoperável, que permite as mais variadas plataformas implementar e dar suporte à este modelo. Existem três grandes elementos que fazem parte dele, e que são responsáveis pela propagação das identidades, a saber:
-
Identity Providers: É o responsável pela validação e emissão de tokens, que são fornecidos para alguém, contendo um conjunto de claims.
-
Relying Parties: A aplicação que recebe e usa esses tokens que são emitidos por algum Identity Provider.
-
Subjects: É alguma coisa ou alguém que possui uma identidade digital (e suas claims), e que na maioria das vezes, representará um usuário.
Cada produto desenvolvido pela Microsoft tem como alvo um dos elementos acima, sendo o ADFS 2.0 uma espécie de identity provider; já o Cardspace permite o gerenciamento das identidades de um subject e, finalmente, o WIF ajuda na construção de aplicações que recebem esses tokens. Como dito anteriormente, todos esses elementos seguem padrões de mercado, e que são rigidamente gerenciados por órgãos independentes. Os protocolos que são utilizados para troca de informações foram desenhados para cruzar limites, que antes deles, eram invioláveis (plataforma e firewalls).
Outro elemento importante que faz parte deste modelo é o Security Token Service (STS). Como o próprio nome diz, trata-se de um serviço que está dentro de um identity provider, e que é responsável por emitir e empacotar as claims que são geradas para alguém, seguindo alguns padrões de mercado que analisaremos mais tarde, ainda neste artigo.
Há algumas técnicas que podem ser utilizadas para criar ambientes baseados em claims. Por exemplo, aplicações web e serviços SOAP (WCF) podem ser considerados relying parties, pois podem fazer uso de claims fornecidas por algum identity provider em nome de alguém. Já o navegador (browser) e aplicações Smart Client, são consideradas os subjects, já que são os responsáveis por gerenciar o fluxo do processo de autenticação, que direta ou indiretamente, irão direcionar o usuário para efetuar a sua autenticação no identity provider em que a aplicação confia.
Quando utilizamos este novo modelo, temos dois ambientes, onde cada um deles trabalha de forma ligeiramente diferente. Esses ambientes são conhecidos como ambiente passivo e ativo. A partir daqui, vamos analisar cada um desses ambientes, tentando abordar como esse modelo trata cada um deles, sem abordar as tecnologias que estão envolvidas. Para ilustrar melhor como cada um deles funciona, vamos analisar a imagem abaixo:
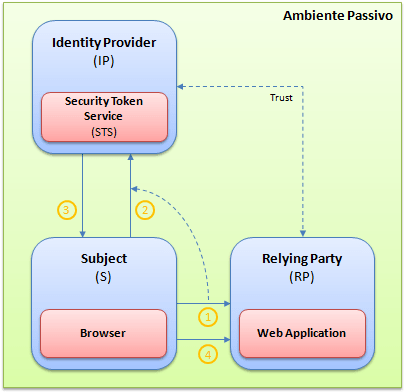
No ambiente passivo, o subject é o browser, enquanto a relying party é uma aplicação web. Quando um usuário requisita uma página que está protegida (1), a aplicação faz essa verificação e nota que o usuário não está autenticado. Com isso, a aplicação redireciona o usuário para o identity provider em que ela confia (2). Este, por sua vez, faz a autenticação do usuário. Aqui não importa o modelo de autenticação que é utilizado (Windows, UserNames, certificados, etc.). Depois de devidamente autenticado, o identity provider retorna o token correspondente aquele usuário (3), que a partir de agora, enviará esse token para todas as requisições subsequentes (4). Como a verificação da existência do token acontece em todas as requisições, uma vez que o usuário estiver autenticado, ele não será mais redirecionado para o identity provider.
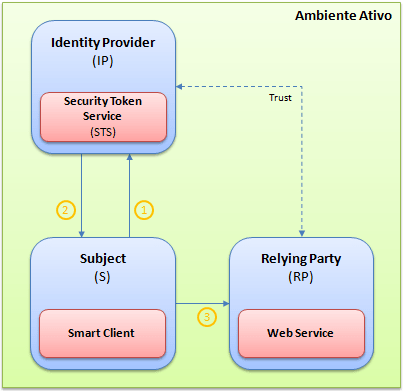
Já no ambiente ativo, o fluxo muda um pouco. Neste cenário, o subject é uma aplicação Smart Client, enquanto a relying party é um serviço SOAP (WCF). O primeiro passo passa a ser a autenticação no respectivo identity provider (1), que uma vez autenticado, um token é emitido para aquele usuário (2). Com isso, todas as requisições irão embutir em seus respectivos headers, o token deste usuário (3). Como a relying party também conhece e confia naquele mesmo identity provider, então o acesso às operações do serviço será garantido.
É importante dizer que no ambiente ativo, o processo acaba sendo mais rápido quando comparado com o ambiente passivo, pois o cliente não precisa visitar o serviço para saber qual é o identity provider que o mesmo utiliza. Isso já aconteceu durante a referência do serviço na aplicação Smart Client, que traz, além da descrição do serviço em si, informações inerentes ao identity provider em que o serviço confia.
Identity Federation
O que vimos acima consiste nos cenários onde todos os participantes estão dentro de um mesmo domínio. Mas um dos principais cenários que este modelo atende, é justamente quando temos os participantes do sistema separados, em domínios diferentes. Da mesma forma que vimos anteriormente, a aplicação ou serviço também poderá aceitar claims que são emitidas por outros identity providers, que estão além do seu domínio, mas que indiretamente há uma relação de confiança estabelecida entre eles. A possibilidade de integração entre os dois domínios também é conhecida como Identity Federation.
Utilizar esta técnica, facilitará muito a possibilidade de SSO (Single Sign-On), que é a possibilidade de se autenticar uma única vez, e reutilizar aquela mesma credencial por todas as aplicações e serviços (relying parties) que aquele usuário utiliza, mesmo que essas aplicações estejam hospedadas nos servidores dos parceiros da nossa empresa. Outro grande ponto positivo desta opção, é que se o usuário não fizer mais parte da minha empresa, tudo o que eu preciso fazer, é remover/desabilitar a sua respectiva conta no meu domínio e, consequentemente, ele não terá mais acesso aos parceiros, já que os parceiros somente confiam em usuários que possuem os tokens emitidos por mim.
Da mesma forma que vimos acima, “cenários federados” também suportam os ambientes passivo e ativo, com mudanças simples no fluxo das informações. E para clarear como o fluxo ocorrerá, vamos utilizar imagens para ilustrar, começando com o ambiente passivo:
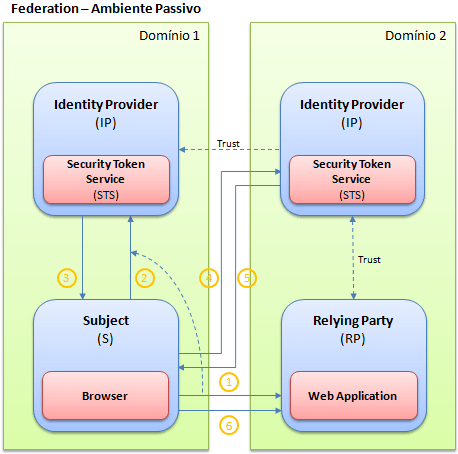
Note que o usuário, que está no domínio 1, tenta acessar uma aplicação web que está hospedada no domínio 2 (1). A aplicação detecta que o usuário ainda não está autenticado, e o redireciona para o identity provider do domínio onde a aplicação está hospedada, que é o orgão que ela confia. Como parte deste redirecionamento, o identity provider do domínio 2 conhece o identity provider do usuário, que está no domínio 1. Isso fará com que o usuário seja novamente redirecionado para o identity provider que o conhece, que é aquele que está debaixo do domínio 1 (2). Ao validar o usuário, o token que o representa dentro da empresa é emitido (3). Depois disso, o token gerado no domínio 1, é encaminhado para o identity provider do domínio 2 (4), que o validará e fará eventuais transformações, criando ou mapeando as claims para claims que a aplicação espera. Isso fará com que um novo token seja emitido (5), e que será utilizado pelo usuário para enviar para as requisições subsequentes (6).
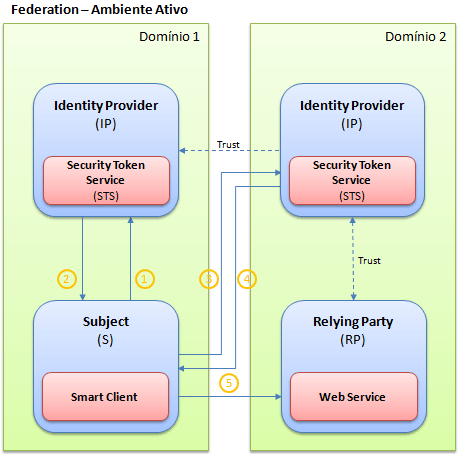
Da mesma forma, o ambiente ativo segue o mesmo fluxo do ambiente passivo, apenas evitando o handshake necessário no ambiente passivo, que é necessário para descobrir qual é o identity provider responsável pela autenticação. Assim como comentado acima, todas as informações necessárias já foram fornecidas durante a referência do serviço, e as requisições (5) já enviarão o token embutido em seus headers.
Observação: Acima vimos os ambientes passivo e ativo sem mencionar os detalhes de implementação de cada um deles. Isso será alvo de futuros artigos, que irão detalhar cada um dos ambientes, mostrando como proceder para configurar cada um deles.
Os Padrões
Uma das principais características que este modelo autenticação e autorização deve ter, é a interoperabilidade entre as partes envolvidas. Como a ideia permitir uma espécie de layer na internet para gerenciar toda a segurança, inclusive entre domínios, uma das principais exigências é a garantia de que toda e qualquer plataforma pudesse tirar proveito disso.
Atualmente já há várias especificações que regem grande parte das comunicações distribuídas entre plataformas, e que são conhecidas como padrões WS-*. Os padrões que compõem as especificações WS-* já estão há bastante tempo no mercado, e são gerenciados por órgãos independentes. Há padrões para grande parte das necessidades que temos hoje em dia nos sistemas distribuídos, tais como: transações, mensagens confiáveis e segurança. Como esses padrões já estão quase todos finalizados, então porque não utilizá-los? É justamente isso que ocorreu, ou seja, grande parte de toda a comunicação que é efetuada entre as partes deste modelo de autenticação, são realizadas seguindo esses padrões, mas felizmente são transparentes para o usuário final, e abstraídas através dos produtos criados pela Microsoft. Abaixo temos esses padrões elencados, com uma breve descrição de cada um deles:
-
WSDL: Descreve quais funcionalidades (operações) são expostas pelo serviço.
-
WS-Policy: O WSDL não descreve nada sobre os requerimentos de segurança necessários para invocar o serviço. O WS-Policy aborda este caso, fornecendo uma forma genérica de descrever os requerimentos de segurança relacionados ao respectivo serviço.
-
WS-Security: Basicamente, este padrão especifica como aplicar a criptografia nas mensagens SOAP, fazendo com que as informações trafeguem de forma protegida, garantindo a confidencialidade e integridade. A forma de segurança aplicada aqui está condicionada ao formato de autenticação que você utilizará entre o subject e o identity provider. Como a interoperabilidade é um dos aspectos mais importantes, o WS-Security efetua a criptografia das mensagens através de token profiles, que descreve como mapear as tecnologias de autenticação que temos atualmente (Kerberos, UserNames, certificados, etc.), para um modelo genérico.
-
WS-SecurityPolicy: Fornece um padrão para representar as capacidades e requerimentos dos serviços através de políticas.
-
WS-Trust: Este padrão fornece extensões para o padrão WS-Security, definindo operações específicas de emissão, renovação e validação de tokens.
-
WS-Federation: Organiza em uma linguagem de mais alto nível os padrões WS-Trust e WS-Security, definindo mecanismos para permitir que a autenticação e autorização sejam feitas entre domínios.
-
WS-MetadataExchange: Permite uma forma de extrair, não somente os dados que descrevem as operações do serviço, mas também todas as funcionalidades (de infraestrutura) expostas por aquele serviço.
Além dos padrões acima, ainda temos o SAML (Security Assertion Markup Language). Enquanto o padrão WS-Security define como inserir as informações dentro do envelope SOAP, o SAML ajuda a definir o que essas informações são. O SAML é uma especificação, também baseada em XML, que permite alguém emitir afirmações a respeito de outro alguém ou para alguma coisa, independentemente da identidade que está sendo utilizada. Entre essas afirmações que fazemos sobre algo, elas também podem descrever os atributos deste alguém, que são também conhecidos como claims.
Como disse acima, o padrão WS-Trust fornece um contrato com quatro operações: Issue, Validate, Renew e Cancel. Cada uma dessas operações autoexplicativas, manipulam tokens que são gerados por um STS para seus subjects. Em todos os ambientes que vimos acima (passivo e ativo), em algum momento há um diálogo entre o subject e o STS do identity provider. Nestes casos, o diálogo é realizado para a emissão (Issue) de um token, que depois de emitido será utilizado para enviar para a aplicação (relying party) que está requerendo. Cada uma das operações expostas troca mensagens conhecidas como RST (Request Security Token) e RSTR (Request Security Token Response), especificadas pelo WS-Trust, que entre várias informações, incluem o tipo de token a ser emitido (que nada mais é que a versão do SAML que está sendo utilizada) e as claims que estão sendo solicitadas pela relying party.
Conclusão: No decorrer neste artigo, analisamos os ambientes possíveis que temos quando trabalhamos com este modelo de autenticação, incluindo o cenário federado. Além disso, analisamos como o fluxo das mensagens acontece nestes ambientes, detalhando em alto nível, os passos necessários para atingir o objetivo. Em futuros artigos, vamos explorar detalhadamente como implementar esse modelo em cada um cenários, analisando como configurar e manter um sistema que faz uso destes elementos.