Imagine que você precise criar um conjunto de componentes que gerenciam a área de recursos humanos de uma determinada empresa. Entre esses componentes, vamos ter um chamado Salario, que dado o nome do funcionário, valor base do salário e a quantidade de horas extras que o funcionário realizou no mês, retorná o valor líquido que a empresa deverá pagar a ele.
Para ilustrar isso, temos um projeto do tipo Class Library, chamado de RegrasDeNegocio. Dentro deste projeto, criamos uma classe chamada Salario, que possuirá apenas o método chamado de Calcular, que receberá os parâmetros mencionados acima. Traduzindo tudo isso em código, teremos algo como:
public class Salario
{
public decimal Calcular(string nomeDoFuncionario, decimal valorBase, decimal horasExtras)
{
return valorBase + horasExtras;
}
}
Note que não há nenhuma complexidade envolvida para não desviarmos o foco. Como sabemos, este projeto dará origem à uma DLL, que poderá ser utilizada por várias aplicações que rodam dentro da empresa. Como já era de se esperar, vamos referenciá-la em um projeto chamado AplicacaoDeRH, que utilizará esse componente recém criado para calcular os salários de seus respectivos funcionários. Com isso, o código de consumo na aplicação final é algo parecido com isso:
Console.WriteLine(new Salario().Calcular(“Israel Aece”, 1000.00M, 250.00M));
Dá mesma forma que antes, vamos manter a simplicidade aqui. Depois deste software (EXE + DLL) instalado na máquina do responsável pelo RH da empresa, eu chego até o diretório físico onde ele está instalado. Copio esses dois arquivos para minha máquina para começar a analisar como esse componente e aplicação foram desenvolvidos. Como sabemos, dentro de qualquer assembly .NET, temos apenas código IL, que é um código ainda decompilável. Podemos utilizar o Reflector para isso e, consequentemente, visualizar tudo o que eles possuem (classes, métodos, parâmetros, etc.).
A partir de agora, vamos explorar a vulnerabilidade. Como eu conheço toda a estrutura que o componente (DLL) tem, nada impede de eu criar um projeto no Visual Studio .NET, com o mesmo nome, com os mesmos tipos e os mesmos parâmetros. Com isso, eu vou manipular o corpo do método Calcular, verificando se o funcionário que está sendo calculado o salário sou eu, e se for, multiplico a quantidade de horas extras por 2, para que eu possa ganhar um valor maior do que realmente deveria.
public class Salario
{
public decimal Calcular(string nomeDoFuncionario, decimal valorBase, decimal horasExtras)
{
if (nomeDoFuncionario == “Israel Aece”)
horasExtras *= 2;
return valorBase + horasExtras;
}
}
Depois de compilado, isso dará origem à uma – nova – DLL com o mesmo nome. De alguma forma, eu chego até o computador do responsável pelo RH da empresa, e substituo fisicamente a DLL anterior por essa DLL que acabamos de desenvolver, e que viola a regra de negócio, pois manipula o resultado para beneficiar um funcionário específico. Com isso, quando o responsável pelo RH for calcular o meu salário, ele me pagará duas vezes o valor das minhas horas extras. Se ele confia cegamente no software que dá o resultado, estou sendo beneficiado, a empresa prejudicada e dificilmente alguém encontrará o problema.
A importância do StrongName
Todo e qualquer assembly possui algumas características que ajudam ao runtime determinar a sua identidade. A identidade de qualquer assembly .NET é composta por quatro informações, a saber: nome, versão, cultura e uma chave pública. O nome nada mais é que o nome do assembly, desconsiderando a sua extensão. A versão é o número em que o projeto se encontra, e que por padrão é 1.0. Já a cultura determina se o assembly é sensitivo à alguma cultura e, finalmente, a chave pública, qual falaremos mais adiante.
Podemos utilizar várias ferramentas para conseguir visualizar essas informações. No nosso caso, se abrirmos dentro do Reflector o componente que criamos inicialmente, aquele que possui o código legal, poderemos comprovar essas características que ajudam a identificar o assembly:
RegrasDeNegocio, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null
Quando criamos a assembly ilegal, com o código que multiplica a quantidade de horas extras por dois, poderemos notar que o resultado será idêntico, ou seja, não há nada que diferencie a identidade dos dois assemblies. Sendo assim, a substituição física é o suficiente para comprometer a regra de cálculo de salário, já que para a aplicação que a consome, acaba sendo o mesmo componente. Se repararmos melhor, entre as quatro informações que compõem a identidade do assembly, uma delas é chamada de PublicKeyToken, e que está nula (não definida). É justamente nela que está a solução para o nosso problema.
Dentro do .NET Framework existem dois tipos de assemblies: os que são fracamente nomeados e os que são fortemente nomeados. Aqueles que são fracamente nomeados (que é o padrão para todos os projetos .NET), são estruturalmente idênticos, possuindo o mesmo formato e os mesmos tipos definidos, mas como está, dá margem para esse tipo de problema.
Isso acontece porque quando efetuamos a referência do componente RegrasDeNegocio.dll na aplicação AplicacaoDeRH.exe, o .NET injeta no manifesto da AplicacaoDeRH, informações pertinentes ao assembly de regras de negócio. Se analisarmos o manifesto do EXE, veremos a seguinte informação:
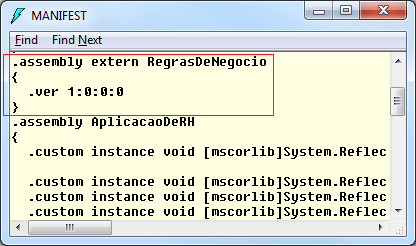
Na imagem acima, podemos verificar que dentro da AplicacaoDeRH há uma referência para o componente RegrasDeNegocio, que inclui o nome e a versão dele. Como até então o componente ilegal possui a mesma identidade, a aplicação consome ele sem maiores problemas, não sabendo que se trata de um componente malicioso.
Para resolver o nosso problema, vamos recorrer aos assemblies fortemente nomeados (strong names). A única e principal diferença em relações aos assemblies fracamente nomeados, é a atribuição de uma chave única, que não se repetirá em nenhum lugar do mundo. A Microsoft criou esse recurso, desde a primeira versão do .NET Framework, que utiliza um par de chaves (pública e privada) para garantir a unicidade do assembly. Antes de ver como elas funcionam, vamos primeiramente entender como gerá-la. O .NET Framework fornece uma ferramenta chamada SN.exe, que é responsável por gerar e manipular essas chaves. Para gerar a nossa chave, podemos executar o seguinte comando (através do prompt do Visual Studio .NET):
SN -k MinhasChaves.snk
O arquivo gerado possui as duas chaves, a pública e a privada e você pode nomear o arquivo da forma que quiser. Com o par de chaves gerado, podemos criar um segundo arquivo para acomodar somente a chave pública, mas em um primeiro momento, isso é desnecessário. A ideia aqui é somente visualizarmos o que temos como chave pública:
SN -p MinhasChaves.snk MinhaChavePublica.snk
Para visualizarmos a chave pública, podemos utilizar o seguinte comando:
SN -tp MinhaChavePublica.snk
Public key is
0024000004800000940000000602000000240000525341310004000001000100f1589e575d9c20
cc36a0fb7245d74c8d69ddc26a0c92ebee5e65dba7c94a6583701176cc5a8fd795e11d7e366c49
a19f3ae28509fa8961e6eca103353fe98168a402dc35001b98d9d5325f6121bde11bc698f268a3
e7e338b950b565be26e371c2550dfaee54f9ef8993dc476f60b2ab5ad69d5ae832ddd7e35e43ad
6daafae2
Public key token is 0b8510fcd7fd739a
Só que o arquivo snk por si só não funciona. Você precisa vinculá-lo ao assembly qual deseja assinar. Para isso, você pode abrir o arquivo AssemblyInfo.cs, e adicionar o atributo AssemblyKeyFileAttribute, que recebe o caminho físico até o arquivo que contém o par de chaves, e que no nosso exemplo é MinhasChaves.snk.
[assembly: AssemblyKeyFile(@”C:MinhasChaves.snk”)]
Ao compilar o assembly com a chave vinculada, veremos que a identidade do assembly já mudará. Ao vincular a chave criada acima no nosso componente RegrasDeNegocio, a identidade irá aparecer da seguinte forma:
RegrasDeNegocio, Version=1.0.0.0, Culture=neutral, PublicKeyToken=0b8510fcd7fd739a
A única e essencial diferença é que agora a propriedade PublicKeyToken reflete exatamente a nossa chave pública, que está contida no arquivo MinhasChaves.snk vinculado ao componente. A partir de agora, as aplicações que referenciarem o componente RegrasDeNegocio, guardarão além do nome e versão do mesmo, a chave pública que o identifica. Depois dessas alterações, se visualizarmos o manifesto da aplicação AplicacaoDeRH, teremos o seguinte resultado:
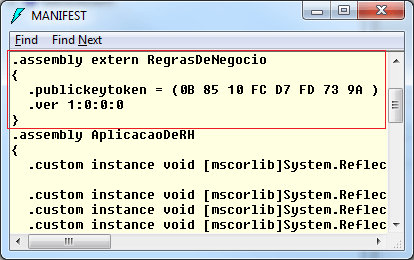
Com isso, qualquer pessoa maliciosa que tente refazer o assembly, por mais que ela se atente a criar toda a estrutura de tipos e métodos, definir o mesmo nome de assembly, e ainda, assinar com um outro strong name, ela jamais conseguirá reproduzir a mesma identidade e, consequentemente, não conseguirá mais alterar o componente que está instalado no cliente. É importante dizer que fisicamente, a substituição ainda poderá ocorrer, mas quando a aplicacação AplicacaoDeRH tentar acessar algum recurso do assembly RegrasDeNegocio, uma exceção será disparada, informando que o assembly solicitado não corresponde aquele que foi inicialmente referenciado.
Observação: Toda essa segurança pode continuar vulnerável se você deixar o arquivo com a chave privada em mãos erradas. Se a pessoa maliciosa conseguir ter acesso a esse arquivo, ela irá gerar o assembly idêntico como ela já fazia, mas ao invés de criar um novo par de chaves para assinar o assembly, ela utilizará o mesmo que você utilizou para assinar o seu, que é o verdadeiro, e com isso todo o problema volta a acontecer.
Para finalizar, vamos entender como todo esse mecanismo funciona e como o runtime do .NET Framework assegura isso. Quando geramos a chave a partir do utilitário SN.exe, um par de chaves é adicionado no arquivo MinhasChaves.snk. Quando compilamos o projeto com esse arquivo vinculado a ele, o .NET gera um hash do componente utilizando o algoritmo SHA1 e assina esse hash com a chave privada. O resultado deste processo é adicionado no próprio assembly, incluindo também a sua chave pública, que está matematicamente relacionada à chave privada. A imagem abaixo ilustra esse processo:

Como vimos acima, quando o componente é referenciado na aplicação que o utiliza, a chave pública também é adicionada à aplicação. Durante a execução, o .NET Framework irá aplicar o mesmo algoritmo de hash no conteúdo do componente (DLL) e dará origem à um novo hash e a chave pública embutida na aplicação que consome aquele componente, será utilizada para extrair o conteúdo (já “hasheado”) que está embutido na DLL do componente. Para determinar se a DLL é a mesma ou não, o resultado do hash deve ser igual, do contrário, a DLL foi substituída e, felizmente, uma exceção será disparada, evitando assim de consumir um componente ilegal. A imagem abaixo ilustra esse processo:

Conclusão: Ao assinar uma aplicação/componente com um strong name, podemos tirar proveito de várias funcionalidades, como por exemplo, o refinamento de segurança, a instalação no GAC, que por sua vez possibilita a centralização, execução lado a lado de múltiplas versões de um mesmo componente, etc. Mas um dos principais benefícios fornecidos por ele, é a unicidade do componente, evitando que alguém consiga reproduzí-lo e, consequentemente, colocar em risco a execução e a confiabilidade das aplicações que a consomem.