Uma das principais técnicas que são utilizadas na Web em busca de performance, é a utilização de técnicas de caching. Com elas, podemos armazenar em algum local uma cópia da página (HTML), arquivo, imagem, etc., que estamos acessando, para quando precisarmos novamente daquele recurso (URL) mais tarde, sermos atendidos de uma forma muito mais rápida.
A redução da latência e a diminuição do tráfego na rede são dois detalhes que alguma estratégia de caching pode ajudar a melhorar. O controle do caching pode estar definido do lado do servidor ou diretamente no cliente que consome o recurso. Sendo assim, ao acessar um recurso que já foi acessado recentemente, o usuário será servido quase que instantaneamente com o – mesmo – resultado.
As estratégias de caching são parte da especificação do protocolo HTTP, que como sabemos, foi desenhado para ser utilizado para acessar informações de sistemas distribuídos. A ideia principal do caching do HTTP, é tentar eliminar, quando possível, a necessidade de fazer novas requisições para um mesmo recurso, ou quando a requisição é necessária, tentar diminuir a quantidade de dados devolvidos.
Na verdade, dois detalhes importantes são definidos na especificação do protocolo, onde a estratégia de caching deve/pode controlar, a saber: expiração e validação. A expiração consiste em verificar se o recurso que está sendo solicitado já está em cache e continua sendo válido (ainda não expirado). Já a validação verifica se o recurso que está sendo re-solicitado ao servidor, sofreu ou não mudanças desde a última requisição, e caso não tenha, nada será retornado, afinal já temos a versão mais atualizada, e isso reduz a quantidade de informações – desnecessárias – sendo trafegadas.
Serviços REST, por estarem fortemente ligados ao protocolo HTTP, podem também fazer uso do caching oferecido pelo protocolo. A ideia deste artigo é demonstrar as opções que temos para configurar e, consequentemente, fazer uso de todos os benefícios oferecidos pelo caching. Para o exemplo, teremos um serviço que gerencia produtos, e haverá um único método que dado um identificador, retorna a instância do produto correspondente. Abaixo temos o código do serviço que utilizaremos pelos exemplos:
[ServiceContract]
[
AspNetCompatibilityRequirements
(
RequirementsMode = AspNetCompatibilityRequirementsMode.Required
)
]
public class Servico
{
[WebGet(UriTemplate = “produtos/{produtoId}”)]
public Produto RecuperarProduto(string produtoId)
{
var produto =
(
from p in produtos
where p.Id == Convert.ToInt32(produtoId)
select p
).SingleOrDefault();
return produto;
}
}
Vou omitir a configuração do serviço aqui, mas neste primeiro momento estaremos utilizando a infraestrutura fornecida pelo WCF para a construção de serviços baseado em REST, que está disponível desde a versão 3.5 do .NET Framework (WCF Web Http). Ao subir este serviço, ele estará acessível e toda e qualquer requisição realizada pelo navegador chegará até o ele.
Todo o controle do caching do HTTP é realizado através de headers que foram criados e são assegurados pelo navegador e pelo servidor, para controlar o caching criado. Os serviços WCF fornecem alguns recursos que nos permitem acessar de forma mais simples estes headers, manipulando-os de acordo com a nossa necessidade. Os headers são divididos em cartegorias para manipular a expiração e a validação, e inicialmente vamos analisar aqueles que são utilizados para determinar a expiração de um recurso.
Expiração
O HTTP 1.1 introduziu um novo header, que é responsável por controlar a expiração. Este header é o Cache-Control, que pode receber vários valores que combinados, instruem o cliente a como efetuar e controlar o caching do recurso que está sendo devolvido. Um dos valores que podemos definir no Cache-Control é private, que determina que aquele conteúdo é exclusivo à um usuário (navegador), e pode eventualmente ser cacheado por ele. Podemos combiná-lo com outro valor que é o max-age, que define um número inteiro, que determina quantos segundos depois da requisição o conteúdo deverá ser mantido no cache.
Sendo assim, podemos recorrer ao contexto da requisição atual (WebOperationContext) dentro do método que está sendo disparado, e lá incluir o header que mencionamos acima. Temos que acessar a coleção de headers a partir da propriedade OutgoingResponse, que permite acessar as informações pertinentes à resposta.
WebOperationContext.Current.OutgoingResponse.Headers.Add(“Cache-Control”, “private, max-age=30”);
Já quando não quiser que o cliente efetue o cache do recurso, podemos recorrer ao mesmo código acima para explicitamente determinar isso, determinando o valor do header Cache-Control como no-cache. O código abaixo exibe esta configuração:
WebOperationContext.Current.OutgoingResponse.Headers.Add(“Cache-Control”, “no-cache”);
Note que para configurarmos o header Cache-Control, utilizamos uma classe pertinente ao WCF, que independe do host que estamos utilizando para hospedar o serviço. Quando utilizamos o IIS e, consequentemente, a infraestrutura do ASP.NET, podemos fazer uso de um recurso que já existe há algum tempo, que é o OutputCache.
A configuração do caching é através de cache profiles, que é um recurso onde você define todas as características do caching no arquivo de configuração (Web.config), e vincula essa configuração através do atributo AspNetCacheProfileAttribute. Abaixo temos o arquivo de configuração do serviço, e podemos notar a configuração do caching. A primeira configuração importante é habilitar o modelo de compatibilidade com o ASP.NET, e fazemos isso através do atributo aspNetCompatibilityEnabled do elemento serviceHostingEnvironment, definindo-o como True.
Em seguida, habilitamos o OutputCache definindo o atributo enableOutputCache como True. Logo após, temos um profile criado, que agrupa o conjunto de configurações de cache e o nomeia. Repare que estamos definindo o local do cache como “Server”, o que determina que uma vez atendida a requisição para um determinado recurso, o cache será armazenado no servidor, e qualquer requisição subsequente, partindo ou não do mesmo cliente, será devolvida do cache criado, respeitando a duração de 60 segundos, ali também configurada. Isso fará com que qualquer complexidade que temos na execução daquele recurso, o preço será pago apenas uma única vez.
<configuration>
<system.web>
<caching>
<outputCache enableOutputCache=”true” />
<outputCacheSettings>
<outputCacheProfiles>
<add name=”CachingNoServidor”
location=”Server”
duration=”60″
varyByParam=”none”/>
</outputCacheProfiles>
</outputCacheSettings>
</caching>
</system.web>
<system.serviceModel>
<serviceHostingEnvironment aspNetCompatibilityEnabled=”true”/>
<services>
<service name=”ViaWcfWebHttp.Servico”>
<endpoint address=””
binding=”webHttpBinding”
contract=”ViaWcfWebHttp.Servico”/>
</service>
</services>
</system.serviceModel>
</configuration>
Como disse anteriormente, a amarração da configuração com o método do serviço é realizada através do atributo AspNetCacheProfileAttribute, que recebe em seu construtor uma string que representa o nome do profile que você quer aplicar para ele. Abaixo temos o serviço que foi ligeiramente modificado, decorado com o respectivo atributo:
[AspNetCacheProfile(“CachingNoServidor”)]
[WebGet(UriTemplate = “produtos/{produtoId}”)]
public Produto RecuperarProduto(string produtoId) { }
Como esse caching refere-se ao servidor, os clientes nada sabem sobre ele. Inclusive na resposta ao cliente, por padrão, ele define o header Cache-Control como no-cache. Como já era de se esperar, podemos criar um novo profile, e lá definirmos o local do cache no cliente. Isso fará com que ao acessar o serviço, o cliente receberá o header Cache-Control definido como private e o atributo max-age definido como 60 (segundos), fazendo com que o navegador faça o caching do recurso. Abaixo temos o trecho do arquivo de configuração que exibe a adição deste profile de caching para o cliente:
<outputCacheSettings>
<outputCacheProfiles>
<add name=”CachingNoCliente”
location=”Client”
duration=”60″
varyByParam=”none”/>
</outputCacheProfiles>
</outputCacheSettings>
Validação
Acima vimos as opções que temos para controlarmos a expiração. Notamos que a expiração controla o período em que o recurso ficará disponível no caching do cliente (ou do servidor). Isso faz com que alguns recursos não sejam requisitados a todo momento, diminuindo a quantidade de informações que trafegam entre as partes. Só que dependendo do conteúdo que está sendo armazenado no cache, nem sempre podemos confiar cegamente no conteúdo que está salvo do lado do cliente.
Em certos cenários, o custo do round-trip é ignorado, em busca dos dados mais recentes possíveis, onde o prejuízo de visualizar uma informação defasada é muito maior. Só que as vezes, vamos até o servidor em busca dessa nova informação, e ela ainda não foi alterada, retornando para o cliente o mesmo conteúdo, atualizando a informação que temos localmente com exatamente, a mesma informação, ou seja, trafegamos uma informação que já tínhamos do lado do cliente. Para otimizar isso, temos uma técnica que chamamos de “GET condicional”.
Essa técnica faz uso de entity tags (ETags), que consiste na adição de um header que é adicionado na resposta à uma requisição, que caracteriza a “versão” do conteúdo que foi devolvido ao cliente. Ao receber esse conteúdo e encaminhar esta tag nas requisições subsequentes, o serviço deverá ser capaz de identificar se houve ou não mudanças no objeto; caso exista, o serviço irá retornar a versão mais recente, do contrário, retornará o status 304 do HTTP, que indica que o recurso não teve mudanças, sem qualquer conteúdo na resposta, poupando assim que informações desnecessárias sejam enviadas ao cliente, que por sua vez, já possue a versão mais atual.
A implementação consiste em duas partes, sendo a primeira onde devemos nos preocupar em passar ao cliente as informações que caracterizam a “versão” do conteúdo, e a segunda parte, onde devemos criar dentro do serviço, a lógica para determinar se a versão que o cliente possui já é ou não a mais recente.
Para nosso exemplo, vamos incrementar a classe Produto com uma propriedade do tipo Guid chamada Versao, que define a versão do mesmo. Qualquer alteração que ocorra em qualquer uma das propriedades do produto, deverá atualizar o GUID. Já que essa propriedade irá caracterizar o versionamento, devemos apontar na resposta para o cliente o seu valor para que ele possa encaminhar ao mesmo através do header ETag. E para isso, vamos novamente recorrer a classe WebOperationContext, acessando a resposta que será enviada ao cliente e, finalmente, teremos o método SetETag, que como o próprio nome diz, permite definirmos a tag:
[WebGet(UriTemplate = “produtos/{produtoId}”)]
public Produto RecuperarProduto(string produtoId)
{
var produto =
(
from p in produtos
where p.Id == Convert.ToInt32(produtoId)
select p
).SingleOrDefault();
WebOperationContext.Current.OutgoingResponse.SetETag(produto.Versao);
return produto;
}
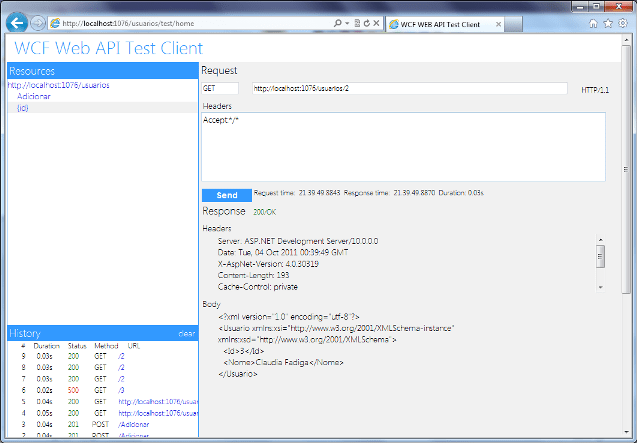
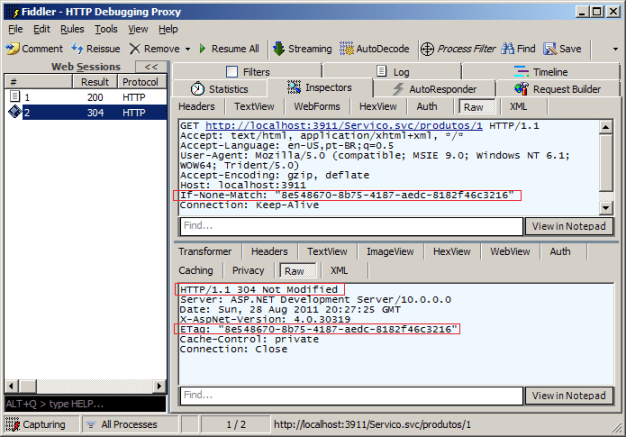
Ao utilizar uma ferramenta para monitorar o tráfego HTTP, podemos visualizar o resultado da requisição para o serviço acima. Note a presença do header ETag definido com o GUID gerado para nosso objeto:
HTTP/1.1 200 OK
Server: ASP.NET Development Server/10.0.0.0
Date: Sun, 28 Aug 2011 20:26:53 GMT
X-AspNet-Version: 4.0.30319
Content-Length: 202
ETag: “8e548670-8b75-4187-aedc-8182f46c3216”
Cache-Control: private
Content-Type: application/xml; charset=utf-8
Connection: Close
<Produto xmlns=”http://schemas.datacontract.org/2004/07/ViaWcfWebHttp” xmlns:i=”http://www.w3.org/2001/XMLSchema-instance”><Descricao>Mouse Microsoft</Descricao><Id>1</Id><Valor>120.00</Valor></Produto>
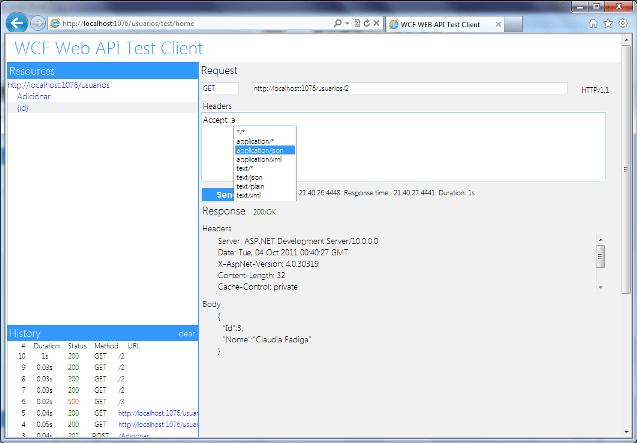
Uma vez que o cliente recepciona essa requisição, as requisições subsequentes repassam o valor do header ETag para o serviço através de um outro header, chamado de If-None-Match, onde o serviço deverá averiguar se o produto foi alterado nesta janela de tempo, para determinar se o conteúdo do cliente deve ou não ser atualizado. Abaixo temos a requisição sendo realizada ao serviço depois de receber a ETag:
GET http://localhost:3911/Servico.svc/produtos/1 HTTP/1.1
Accept: text/html, application/xhtml+xml, */*
Accept-Language: en-US,pt-BR;q=0.5
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)
Accept-Encoding: gzip, deflate
Host: localhost:3911
If-None-Match: “8e548670-8b75-4187-aedc-8182f46c3216”
Connection: Keep-Alive
Para efetuar essa validação do lado do serviço, há um método chamado CheckConditionalRetrieve, que está disponível a partir da propriedade IncomingRequest da classe WebOperationContext. Esse método recebe como parâmetro a ETag do produto. Se o produto não foi modificado, então a tag da requisição será a mesma, o que faz com que o método, internamente, aborte a requisição, devolvendo ao cliente o resultado 304 do HTTP, que caracteriza que nada foi mudado (NotModified). O código a seguir exibe a utilização deste método, e logo na sequência, temos a imagem que ilustra esse procedimento:
[WebGet(UriTemplate = “produtos/{produtoId}”)]
public Produto RecuperarProduto(string produtoId)
{
var produto =
(
from p int produtos
where p.Id == Convert.ToInt32(produtoId)
select p
).SingleOrDefault();
WebOperationContext.Current.IncomingRequest.CheckConditionalRetrieve(produto.Versao);
WebOperationContext.Current.OutgoingResponse.SetETag(produto.Versao);
return produto;
}
WCF Web API
Como já comentei aqui, a Microsoft trabalha em um novo projeto chamado WCF Web API, que torna o desenvolvimento e consumo de serviços REST mais simples. Estes tipos de serviços também podem tirar proveito dos recursos de caching fornecidos pelo HTTP que vimos neste artigo.
Ao utilizar os objetos que representam as mensagens de requisição e resposta diretamente, você encontrá propriedades que configuram o caching no cliente. Você também pode optar por utilizar um message handler, para separar o que corresponde ao negócio do que compete a parte de infraestrutura.